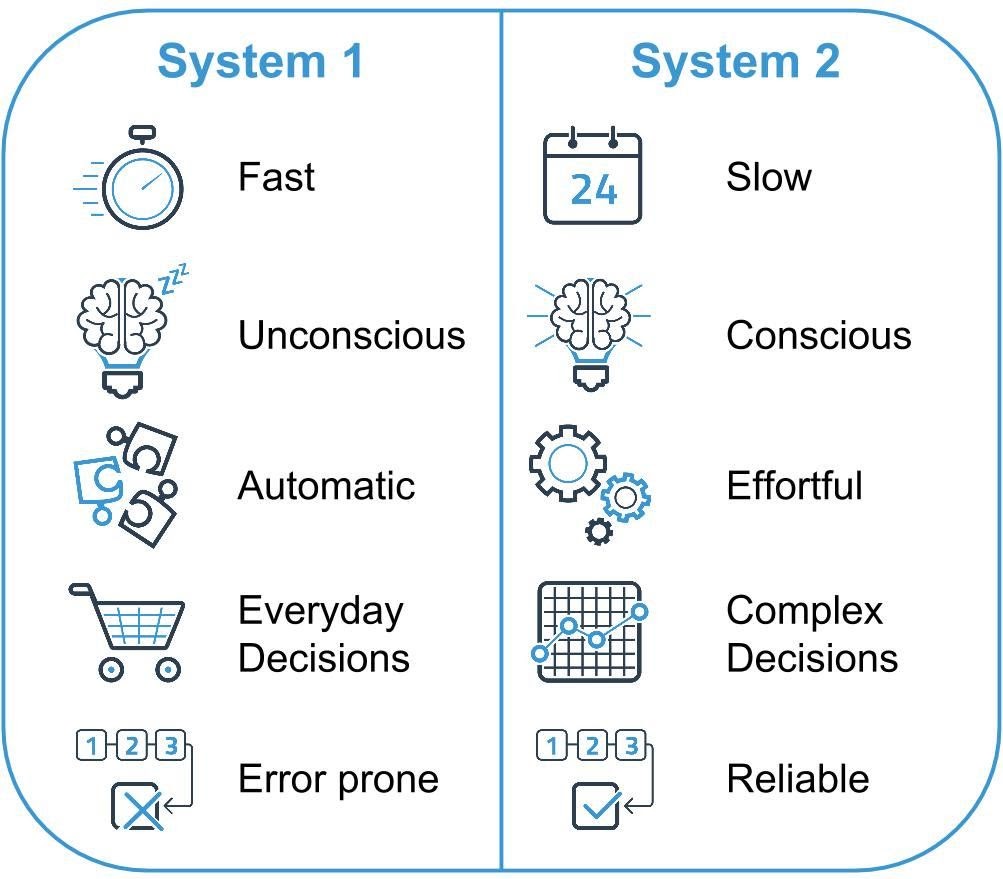
A forma humana de pensar
Em seu livro: “Rápido e Devagar: duas formas de pensar”, Daniel Kahneman apresenta dois modos de pensamentos, que os chama de sistemas 1 e 2.
- O Sistema 1 corresponde ao pensamento rápido e automático, feito intuitivamente;
- O Sistema 2 corresponde ao pensamento devagar, geralmente utilizado para atividades que exigem concentração.
As operações automáticas do Sistema 1 geram padrões de ideias surpreendentemente complexos, mas apenas o Sistema 2, mais lento, pode construir pensamentos em séries ordenadas de passos.
Vamos a um exemplo prático para entender:
Tente determinar, rapidamente, se o argumento é logicamente válido:
Todas as rosas são flores.
Algumas flores murcham rápido.
Logo, algumas rosas murcham rápido.
A grande maioria, pensando rapidamente, toma a conclusão acima como válida, mas na verdade o argumento é falho, pois algumas rosas podem não estar no grupo das flores que murcham rápido. E, analisando cuidadosamente, se necessário fazendo uma tabela verdade, chegamos na resposta correta.
Comparando com Deep Reinforcement Learning
Comparando os sistemas de pensamento humanos com algoritmos de Deep Reinforcement Learning (RL), as redes neurais estabelecem padrões e realizam predições automaticamente a partir de generalizações e tendências consideradas, podendo correlacionarmos com o nosso Sistema 1. As decisões são tomadas rapidamente, similarmente ao Sistema 1.
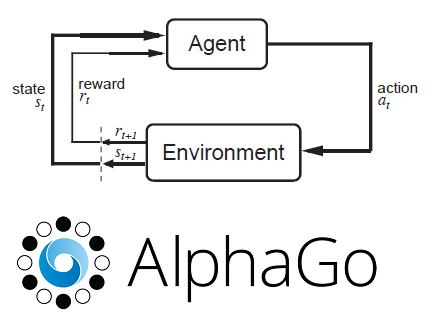
O que é Deep Reinforcement Learning?
É um técnica que combina redes neurais artificiais com aprendizado por reforço (reinforcement learning, em inglês, uma área de aprendizado de máquina) que consiste em treinar um agente para que ele aprenda as melhores ações possíveis em determinado ambiente para atingir seus objetivos.
O jogo AlphaGo
A primeira versão do jogo Alpha Go, criado pela DeepMind, é um ótimo exemplo de Deep Reinforcement Learning, e se assemelha ao nosso S1: ele (agente) aprende e decide as melhores jogadas rapidamente, mas possui tendências, já que o agente RL imita os movimentos de um expert e, somente, após essa fase inicial ele começa a aprender um jogo potencialmente mais poderoso.
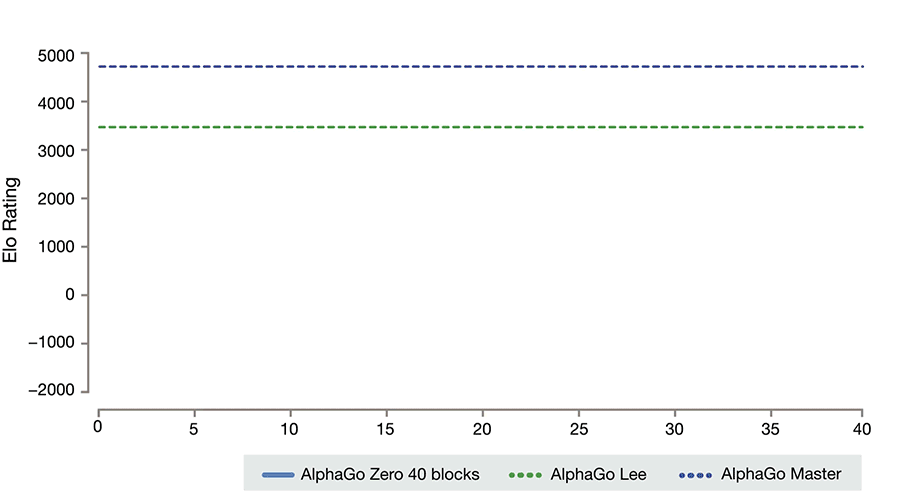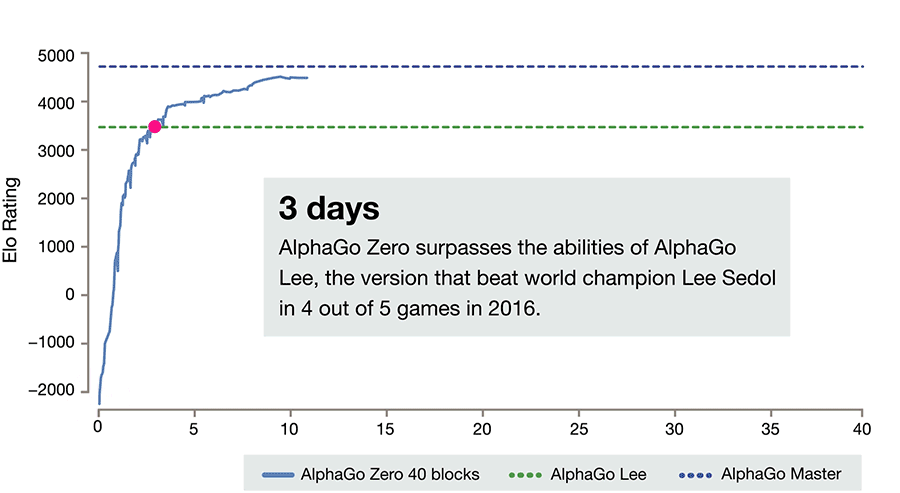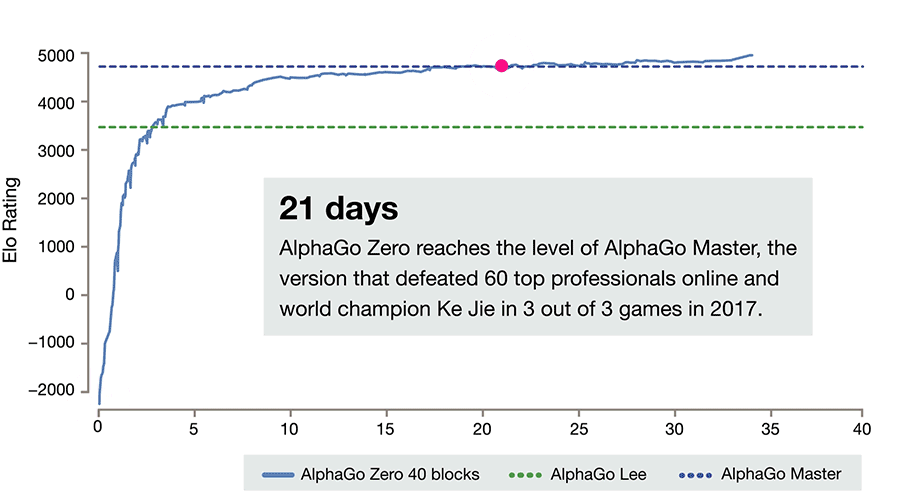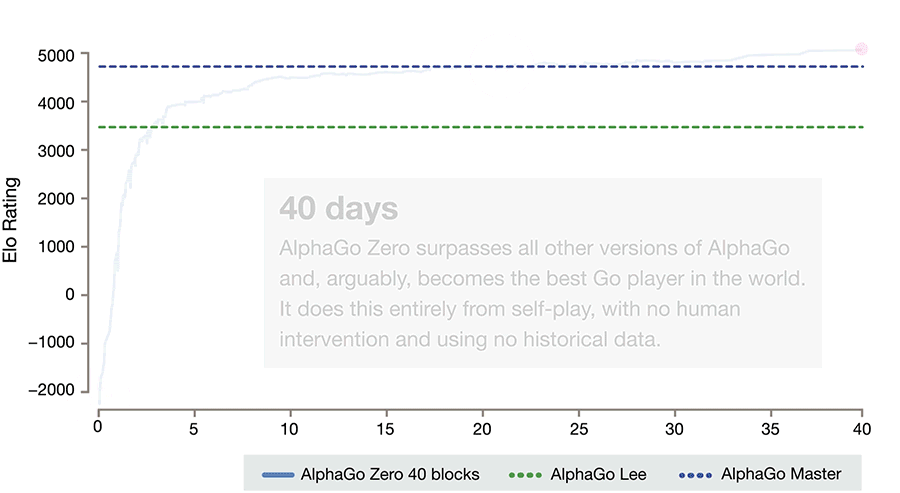
Mas o potencial computacional vem avançando e algoritmos foram e estão sendo criados para não depender da atividade humana para serem treinados. O Expert Interaction (ExIt) - um novo algoritmo de Reinforcement Learning - utiliza árvore de busca, que auxilia o treinamento da rede neural, análogo com o que acontece com o nosso Sistema 2, e por sua vez a rede neural melhora o desempenho da árvore de busca, fornecendo intuições rápidas para orientar a busca.
O Alpha Go Zero utiliza essa nova técnica de aprendizado, na qual ele se torna seu próprio professor. O sistema começa com uma rede neural que não sabe nada sobre o jogo Go. Em seguida, ele joga contra si mesmo, combinando essa rede neural com um poderoso algoritmo de busca. Enquanto joga, a rede neural é ajustada e atualizada para prever jogadas.
Referências
Thinking Fast and Slowwith Deep Learning and Tree Search


Comentários